List of Ongoing Research Projects
Energy Efficient and Resilient Resource Allocation for High Performance Computing
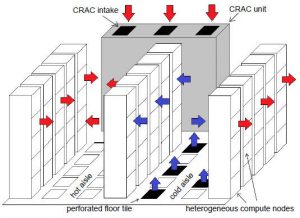
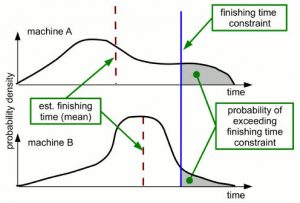
Parallel and distributed high performance computing (HPC) systems are often a heterogeneous mix of machines. As these systems continue to expand rapidly in capability, driven by the call of exascale and growing demand for cloud computing, their computational energy expenditure has skyrocketed, requiring elaborate cooling facilities to function, which themselves consume significant energy. The need for energy-efficient resource management is thus paramount. Moreover, these systems frequently experience degraded performance and high power consumption due to circumstances that change unpredictably, such as thermal hotspots caused by load imbalances or sudden machine failures. As the complexity of systems grows, so does the importance of making system operation robust against these uncertainties. The research objective of this project is the design of models, metrics, and algorithmic strategies for deriving resource (e.g., workload, data) allocations that are energy-efficient and robust. The focus is on deriving stochastic robustness and energy models from real-world data; applying these models for resource management strategies that co-optimize performance, robustness, computation energy, and cooling energy; modeling the impact of interference in shared memory and network subsystems; quantifying task and machine heterogeneity; thermal setpoint adaptation to save energy; developing schemes for real-time thermal modeling; defining new metrics to characterize cooling energy costs and capacity; and driving and validating our research based on feedback collected from real-world petaflop systems (Yellowstone at National Center of Atmospheric Research, Titan at Oak Ridge National Lab) and teraflop systems (CSU’s Cray cluster, teraflop cluster at Oak Ridge National Lab).
Fault Resilient Exascale Computing
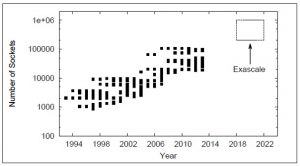
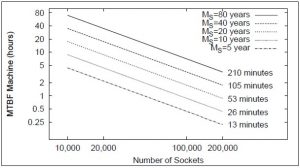
With the increase in the complexity and number of nodes in large-scale high performance computing (HPC) systems, the probability of applications experiencing failures has increased significantly. As the computational demands of applications that execute on HPC systems increase, projections indicate that applications executing on exascale-sized systems are likely to operate with a mean time between failures (MTBF) of as little as a few minutes. A number of strategies for enabling fault resilience in systems of extreme sizes have been proposed in recent years. However, few studies provide performance comparisons for these resilience techniques. The research objective of this project is to analyze existing state-of-the-art HPC resilience techniques that are being considered for use in exascale systems.The goal is to explore the behavior of each resilience technique for a diverse set of applications varying in communication behavior and memory use, and design new resilience techniques with better scalability. We aim to examine how resilience techniques behaves as application size scales from what is considered large today through to exascale-sized applications. We further propose to study the performance degradation that a large-scale system experiences from the overhead associated with each resilience technique as well as the application computation needed to continue execution when a failure occurs. We will also examine how application performance on exascale systems can be improved by allowing the system to select the optimal resilience technique to use in an application-specific manner, depending upon each application’s execution characteristics.