
A quick overview of the various research activities in our lab can be found in the poster here. Link to all relevant publications can be found here. Citations and publications are also listed at: [Google Scholar] [DBLP]

List of Ongoing Research Projects
- CAD Tools for Multi-Objective Multicore Architecture Design
- Design for Emerging Memory Architectures
List of Past Research Projects
Silicon Photonics for Multicore Computing
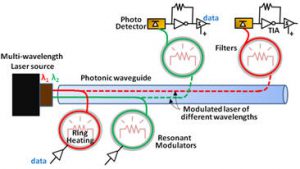
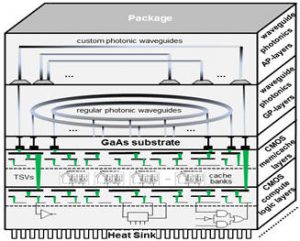
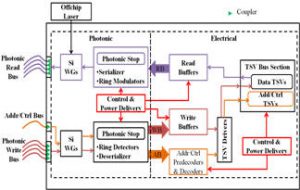
Enabling high bandwidth and power-efficient communication between information processing cores in System-on-Chip (SoC) architectures is an essential but increasingly difficult aspect of electronic chip design. SoCs play a pivotal role in society today, as these application-specific high-performance VLSI circuits drive all major modern inventions including vehicles and airplanes, computers and phones, scientific and industrial infrastructure, as well as military systems. With SoC processing core counts increasing steadily every year to enable more sophisticated applications (e.g., high fidelity target discrimination, warfighter control and navigation), the demands of higher bandwidth and low latency transfers are putting greater pressure on SoC communication networks. The result is that chip power and performance are now dominated not by processor cores but by the network that transports data between processors and to memory. In other words, SoC robustness and quality is now network dominated. The research objective of this project is to determine the best architectural modalities to insert silicon photonic interconnect technology into electronic chips, in order to overcome performance and energy bottlenecks in today’s SoCs. The project involves creating performance, energy, and reliability models, circuits, architectures, and optimization techniques, to expedite the deployment of silicon photonics into manycore SoCs in the near future, to overcome the severe shortcomings of electrical interconnects at the chip-scale.
Cross-Layer Design of Interconnection Networks-on-Chip
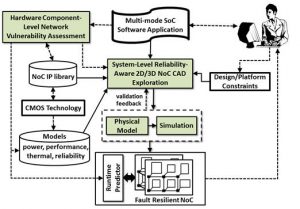
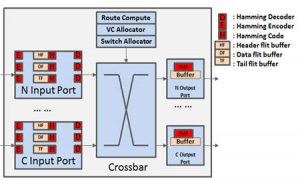
Shrinking feature sizes and the increasing proliferation of mixed-signal and 3D integration are elevating rates of faults, variation, and aging related degradation in integrated circuits, threatening the reliability of communication between cores in system-on-chip (SoC) architectures. It is well known that performance for most SoCs today is interconnect-limited and the design of a high performance network-on-chip (NoC) will become a crucial step as core counts increase from tens today to hundreds in the near future, and 3D die stacking becomes the norm. But the NoC is a key component for another reason: it constitutes a single point of failure on a chip. Mechanisms for fault detection and recovery are thus vital for NoCs, especially in 3D ICs where greater thermal stress due to higher temperatures and thermal cycling accelerates a multitude of degradation affects, increasing transient and permanent fault rates at runtime. Unfortunately, current techniques to ensure NoC reliability at runtime, including fault tolerant routing, and architectural solutions operate at only one level of the system stack. Such single-layer techniques possess limited knowledge of application execution activity, and are therefore reactive in behavior, making worst-case assumptions about other layers. As a result, they introduce significant power, area, and performance overheads during typical-case operation for corner-case errors that occur very infrequently. The research objective of this project is to realize a multi-objective computer-aided design (CAD) automation framework at the system-level, where design decisions have the most impact, to assist chip designers trade-off reliability with competing design constraints within tight time-to-market constraints. This framework is novel as it will exploit cross-layer insights about the software application, hardware IP blocks, and circuits, as well as knowledge of key factors impacting susceptibility to runtime faults for NoC routers and interfaces. The research aims to create novel tools and techniques that will have a significant impact in industry by improving designer productivity and ushering in new levels of cost-efficiency during the reliable-by-construction design of network fabrics for SoCs.
CAD Tools for Multi-Objective Multicore Architecture Design
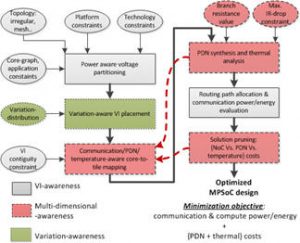
With increasing core counts ushering in power-constrained multiprocessor system-on-chips (MPSoCs), optimizing power dissipated by the computation cores and the network-on-chip (NoC) fabric is critical. At the same time, with increased power densities, especially in 3D ICs, problems of IR drops in the Power Delivery Network (PDN) as well as thermal hot spots on the die are very severe. Additionally, variations in emerging fabrication processes introduce significant unpredictability in system behavior. System-level design approaches that are aware of these challenges are crucial for designing efficient MPSoCs. This project recognizes that for each new configuration of computation core and communication mapping on an MPSoC, the corresponding inter-core communication patterns, 3D on-chip thermal profile, IR-drop distribution in the PDN, as well as impact of process variations on system performance can vary significantly. Based on this key observation, the research objective of this project is to design a novel system-level co-synthesis framework that intelligently maps computation and communication resources on a die to minimize overall system power (including computation, communication and chip-cooling power) and optimize the PDN architecture; while meeting performance goals and satisfying thermal constraints. The project also considers emerging challenges for multicore computing at runtime, such as soft and hard errors, dim and dark silicon, and process/voltage/thermal (PVT) variations.
Design for Emerging Memory Architectures

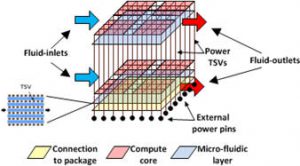
On-chip memory architectures in multi-core systems can occupy up to 70% of the die area and have a significant impact on system cost, performance, power dissipation, and time-to-market. Off-chip memory is not expected to scale well for high performance computing systems of the future. Designers must therefore carefully explore the memory hierarchy design space to select the appropriate scratchpad memories, caches, SRAM, DRAM, and emerging non-volatile memories to optimize for desired design constraints. The research objective of this project is to investigate the memory requirements of modern parallel applications and understand its interactions with the on-chip communication infrastructure and other components on a manycore chip. The research focus of this exploration is to eventually design new memory components and architectures as well as CAD techniques and tools to assist the designer in optimizing the memory hierarchy for future manycore architectures. The project focuses on 3D stacked DRAM, phase-change RAM (PCRAM), spin-torque RAM (STT-RAM), and memory controller design strategies for high performance, predictable latency, low energy, and high reliability.
Energy Efficient and Resilient Resource Allocation for High Performance Computing
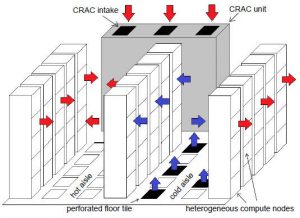
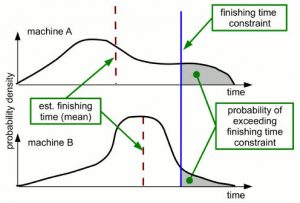
Parallel and distributed high performance computing (HPC) systems are often a heterogeneous mix of machines. As these systems continue to expand rapidly in capability, driven by the call of exascale and growing demand for cloud computing, their computational energy expenditure has skyrocketed, requiring elaborate cooling facilities to function, which themselves consume significant energy. The need for energy-efficient resource management is thus paramount. Moreover, these systems frequently experience degraded performance and high power consumption due to circumstances that change unpredictably, such as thermal hotspots caused by load imbalances or sudden machine failures. As the complexity of systems grows, so does the importance of making system operation robust against these uncertainties. The research objective of this project is the design of models, metrics, and algorithmic strategies for deriving resource (e.g., workload, data) allocations that are energy-efficient and robust. The focus is on deriving stochastic robustness and energy models from real-world data; applying these models for resource management strategies that co-optimize performance, robustness, computation energy, and cooling energy; modeling the impact of interference in shared memory and network subsystems; quantifying task and machine heterogeneity; thermal setpoint adaptation to save energy; developing schemes for real-time thermal modeling; defining new metrics to characterize cooling energy costs and capacity; and driving and validating our research based on feedback collected from real-world petaflop systems (Yellowstone at National Center of Atmospheric Research, Titan at Oak Ridge National Lab) and teraflop systems (CSU’s Cray cluster, teraflop cluster at Oak Ridge National Lab).
Fault Resilient Exascale Computing
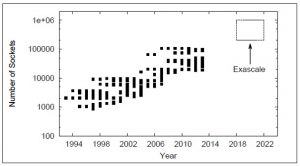
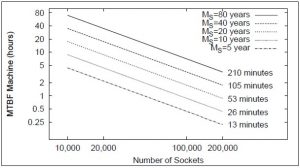
With the increase in the complexity and number of nodes in large-scale high performance computing (HPC) systems, the probability of applications experiencing failures has increased significantly. As the computational demands of applications that execute on HPC systems increase, projections indicate that applications executing on exascale-sized systems are likely to operate with a mean time between failures (MTBF) of as little as a few minutes. A number of strategies for enabling fault resilience in systems of extreme sizes have been proposed in recent years. However, few studies provide performance comparisons for these resilience techniques. The research objective of this project is to analyze existing state-of-the-art HPC resilience techniques that are being considered for use in exascale systems.The goal is to explore the behavior of each resilience technique for a diverse set of applications varying in communication behavior and memory use, and design new resilience techniques with better scalability. We aim to examine how resilience techniques behaves as application size scales from what is considered large today through to exascale-sized applications. We further propose to study the performance degradation that a large-scale system experiences from the overhead associated with each resilience technique as well as the application computation needed to continue execution when a failure occurs. We will also examine how application performance on exascale systems can be improved by allowing the system to select the optimal resilience technique to use in an application-specific manner, depending upon each application’s execution characteristics.
Indoor Localization with Smartphones
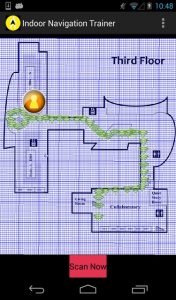

Global Navigation Satellite Systems (GNSS) have transformed the way that people navigate, travel, automate, and gather information about the world around them. Indoor localization systems have the potential to similarly change how people function in locations where satellite-based localization systems are rendered ineffective. There is a need for systems that can bridge this gap and create continuity in localization regardless of location. However, indoor localization is a challenging problem, particularly in complex indoor spaces such as shopping malls, schools, high-rise buildings, hospitals, subways, tunnels, and mines. These variety of locales involve differing ambient environments, obstructions, architectures, and materials, which makes accurate localization difficult. There are also challenges associated with the movement of people, machinery, furniture, and equipment that cause variation and interference. There are many different approaches to localizing indoors, but unfortunately there is currently no definitive standard to meet all the needs and challenges for localization in every indoor environment. The ability to track people and equipment indoors has applications in many areas. Factory and warehouse automation through asset tracking and optimization analysis can serve to increase productivity by effectively scheduling resources and equipment. Hospitals can track patients, employees, and equipment to enhance navigation and allow for the automation of hospital information systems. Retail stores can use beacons to announce sales, customize displays to the shopper, collect shopping pattern data, and assist customers in finding products. Parking garages and underground parking structures could track fill capacity, direct vehicles to open spots, locate vehicles, and ultimately enhance autonomous vehicle routing. Tracking people can not only help to find family or friends in a crowd but could also be used by emergency responders in the case of a disaster. The research objective of this project is to develop new techniques to improve the accuracy, reliability, and energy-efficiency of indoor localization and navigation. The goal is to utilize commodity devices such as smartphones and as much of existing infrastructure deployment (e.g., WiFi access points) to aid with localization.
Middleware Optimizations for Smart Mobile Computing
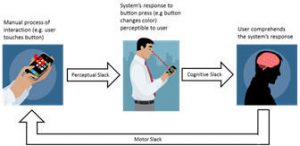
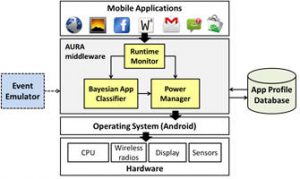
App-enabled smartphones have been outselling PCs for the past several years. The portability, compact form factor, and feature rich convergence capabilities of app-based devices have fueled their rapid adoption by consumers. However that future growth of this computing paradigm will be critically hampered by battery technology limitations that today make it impossible to operate these devices beyond a few hours for common use cases such as watching streaming video or using the GPS. Often, users end up having to manually shut down location services, turn off Wi-Fi radio, reduce backlight brightness, etc. to extend battery lifetime. These steps are not only cumbersome but also disrupt opportunities for ambient intelligence and collaborative computing. If the several well publicized reports of excessive battery drain in the latest app-based portable devices are any indication, the manner in which energy is optimized in app-based devices requires a radical rethink. The research objective of this project is to achieve aggressive battery lifetime enhancements for app-based portable computing devices via a coordinated cross layer effort that bridges the gap between user, software application, OS, and hardware component levels. The research focus is on a self-reconfigurable middleware layer that continuously rearranges and tunes available functional and non-functional components into value-added and tailored aggregations that optimize energy consumption. The research aims to derive insights from cross-platform and cross-device profiling studies to develop models for user interaction, battery discharge, and context estimation. The project exploits machine learning techniques as well as new models ofcomputation, e.g., offloading computation from the device to the cloud in an opportunistic manner at runtime.
Automotive ADAS and Network Design
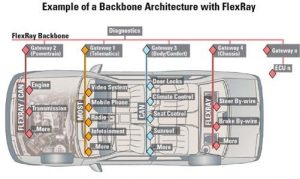
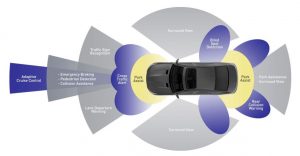
Advanced driver-assistance systems (ADAS) are systems developed to automate/adapt/enhance vehicle systems for safety and better driving. Safety features are designed to avoid collisions and accidents by offering technologies that alert the driver to potential problems, or to avoid collisions by implementing safeguards and taking over control of the vehicle. Adaptive features may automate lighting, provide adaptive cruise control, automate braking, incorporate GPS/ traffic warnings, connect to smartphones, alert driver to other cars or dangers, keep the driver in the correct lane, or show what is in blind spots. At the same time, the distributed network in vehicles presents a key design challenge to realizing a safe and high performance operation. The research objective of this project is to 1) design new ADAS techniques that rely on low-power image recognition, machine learning techniques, and smart sensor fusion, and 2) design automotive networks and techniques for scheduling messages on these automotive networks (based on Flexray, CAN, TTEthernet, etc.) in manner that is jitter-resilient, secure, and adheres to real-time timing constraints.
Embedded Systems for Robotics and Automation




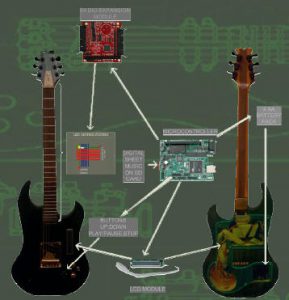




Embedded systems are ubiquitous and at the heart of innovation happening in numerous application domains today, such as in automotive, aerospace, networking, medical, consumer and home electronics, industry automation, smart grid, robotics, and supercomputing. This project has an open-ended research objective of utilizing embedded systems in various application domains to enhance the capabilities and intelligence embedded inside a target application. We have designed numerous working prototypes that employ embedded computing systems, as part of this project: flying drones with Kinect-based reconnaissance capabilities, mobile robots for emergency rescue and land mine detection using smart sensors and vision algorithms, interactive teaching guitars with FPGAs, brewery automation with multiple distributed micro-controllers, solar energy harvesting based computing platforms, smartphone controlled deadbolts, car and home automation systems, and robots, and wearable computing systems using flexible, lightweight, and networked computing devices.
Serious Games for Rehabilitation

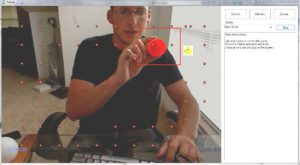

Strokes affect around 700,000 Americans annually, and cerebral palsy (CP) affects 17 million people. These diseases cause upper limb impairments in roughly 40 to 50 percent of the victims. In order to combat the issues brought upon by these debilitating conditions, upper limb rehabilitation is needed. However, rehabilitation can be very tedious; and as a result, patients sometimes give up on the rehabilitation because they do not have the motivation to go through with it. As a result, those who suffer from debilitating diseases lack the quality of life that they once had. The research objective of this project was to help improve the quality of life for the people afflicted with these diseases using augmented reality and virtual reality games. The project involved computer and electrical engineering students working along with occupational therapy students to create an interface for these patients to perform their rehabilitation in a new and more motivating/entertaining environment.
The GATOR project has evolved from a simple suite of games that use a webcam and a computer, to more sophisticated offerings utilizing augmented reality, virtual reality, Kinect sensors and more recently the Leap motion controller. GATOR features games and activities that provide positive reinforcement as well as an enjoyable experience for the patient. Developed with JavaScript, HTML5, the suite of games use 2D and 3D game play to give patients the ability to exercise their limbs in an XY plane as well as an XYZ plane. The Leap Motion controller is able to track the user’s hand movement in the X Y and
Z planes as well as gestures that can interpret grabbing and pointing among others. The entire framework ultimately enables low-cost in-home rehabilitation, drastically reducing the cost for therapy.
Design and Exploration of Energy Harvesting Real-Time Multicore Embedded Systems
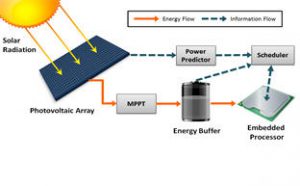
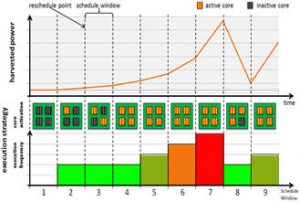
Power and energy constraints have enforced significant change in the design of contemporary computing systems. Due to unacceptable power consumption at higher clock rates and more potent power leakage with technology scaling, single-thread performance has been slowing down. Thus thread-level parallelism (TLP) to improve performance within a given power budget is widely practiced across various computing platforms, ranging from high-end servers to desktops, as well as embedded devices. Recent years have also seen a significant increase in popularity of multi-core processors in low power embedded devices. With advances in parallel programming and power management techniques, embedded devices with multicore processors and TLP support outperform single-core platforms in terms of both performance and energy efficiency. But as core counts rise to cope with increasingly complex applications, techniques for workload distribution and power management are the key to achieving significant energy savings in emerging multi-core embedded systems. For some applications, we need energy autonomous devices that utilize ambient energy to perform computations without relying entirely on an external power supply or frequent battery charges. As the most widely available energy source, solar power harvesting has attracted a lot of attention and is rapidly gaining momentum. The research objective of this project was to design novel techniques for real-time workload and communication allocation on multi-core platforms that exploit energy harvesting. The research focus has been on designing frameworks that can react to rapidly changing energy availability at runtime, efficient approaches for energy storage, and an emphasis on thermal-awareness as well as fault-tolerance. As an example of such a framework, we proposed a hybrid design-time/run-time framework for resource allocation that takes into consideration variations in solar radiance and execution time, transient faults, and permanent faults due to aging effects. Our framework generated schedule templates at design-time with an emphasis on energy efficiency and uses lightweight online management schemes to react to run-time system dynamics. Experimental results indicated that our framework presents improvements in performance and adaptivity, with up to 23.2% miss rate reduction compared to prior work, 43.6% performance benefits from adaptive run-time workload management, and up to 24.5 % expected system lifetime improvement with aging-aware allocation of workload partitions.
System-Level Modeling for Power and Performance Analysis of Multicore SoCs
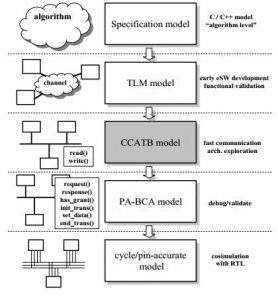
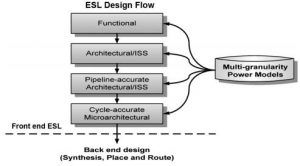
To perform early, system-level exploration of processors, memories, and the on-chip communication architecture, designers require a fast and accurate simulation framework. To address this challenge, the research objective of this project was to design several fast and accurate simulation and estimation frameworks for performance and power evaluation early in the design flow at the system-level. We proposed a novel modeling abstraction called CCATB that allows fast and accurate simulation-based exploration. The CCATB simulation kernel optimally aggregates the delays encountered within a read or write transaction and increments simulation time by multiple cycles wherever possible. This considerably reduces the event scheduling overhead during simulation. The simulation abstraction maintains overall cycle accuracy, while trading off intra-transaction visibility for simulation and modeling speedup. CCATB models of industrial strength MPSoC designs were shown to be more than a 1000X faster than RTL simulation and more than 2X faster than the fastest previously proposed abstraction for communication architecture exploration. Our system-level power modeling framework was shown to be 2000X faster than gate level estimation tools while maintaining more than 95% accuracy.
Design and Exploration of On-Chip Communication Architectures
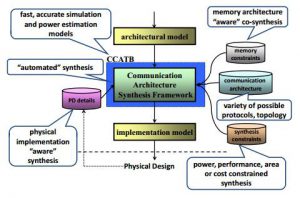
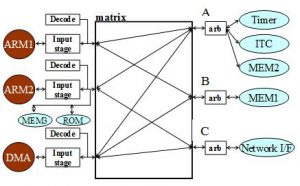
Modern multi-processor system-on-chip (MPSoC) designs are rapidly increasing in complexity, as more and more components are integrated on a single chip. The on-chip communication architecture in such systems must handle the entire inter-component data traffic, and has been shown to have a critical impact on system performance and power consumption. Additionally, the design, customization, exploration and implementation of on-chip communication architectures take up a considerable chunk of the design cycle, affecting time-to-market. These observations motivate the need for a methodology to explore and synthesize on-chip communication architectures earlier in the design flow, at the system level, where design decisions have the greatest impact. To address these requirements, the research objective of this project was to design the COMMSYN framework for automated on-chip communication architecture exploration and synthesis. Unlike existing approaches, COMMSYN enables a physical-implementation aware and memory architecture aware on-chip communication architecture synthesis, comprehensively generating both the topology and parameters (such as clock frequency, data width, arbitration scheme and buffer size), while trading off multiple design constraints such as power, performance, area and cost. Our approach was one of the first to integrate physical floorplan awareness during system-level analysis and exploration. Our memory and communication architecture co-synthesis framework was shown to reduce memory area by as much as 30%, and the number of buses by 40%, compared to traditional approaches where memory and communication architectures are synthesized separately. Our framework to synthesize partial bus matrix communication architectures provided up to a 9X reduction in bus count for complex, industrial strength MPSoC applications, which has significant implications for cost and chip area.
Carbon Nanotube Based On-Chip Interconnect Architectures
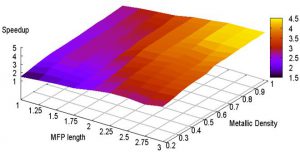
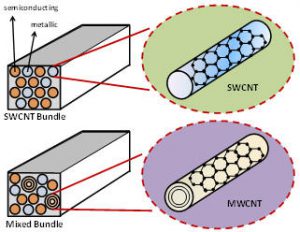
According to the International Roadmap for Semiconductors (ITRS), global interconnect performance has become one of the semiconductor industry’s topmost challenges. Conventional copper (Cu) global interconnects have become increasingly susceptible to electromigration at high current densities (>10^6 A/cm2) leading to considerable degradation in reliability. Additionally, as interconnect dimensions are scaled down, rising crosstalk coupling noise and parasitic resistivity due to electron-surface and grain-boundary scatterings cause global interconnect delay to increase rapidly. There is therefore a critical need to investigate innovative global interconnect alternatives to Cu. Recently, there has been tremendous interest in carbon nanotubes (CNTs) as a possible replacement for Cu interconnects in future technologies. Depending on the direction in which they are rolled (referred to as chirality) CNTs can behave either as semiconductors or conductors. Conducting (or metallic) CNTs possess many extraordinary properties that make them promising candidates for implementing interconnects in UDSM technologies. Due to their covalently bonded structure, they are highly resistant to electromigration and other sources of physical breakdown. They can support very high current densities with very little performance degradation. They also have much better conductivity properties than Cu owing to longer electron mean free path (MFP) lengths in the micrometer range, compared to nanometer range MFP lengths for Cu interconnects. CNTs can be broadly classified into single-walled carbon nanotubes (SWCNTs) and multi-walled carbon nanotubes (MWCNTs). SWCNTs consist of a single sheet of graphene rolled into a cylindrical tube, with a diameter in the nanometer range. MWCNTs consist of two or more SWCNTs concentrically wrapped around each other, with diameters ranging from a few to several hundred nanometers. For on-chip global interconnects, bundles of SWCNTs and mixed SWCNT/MWCNTs are also of special interest because of their superior conductivity properties. An SWCNT bundle consists of several SWCNTs packed together in parallel, whereas a mixed SWCNT/ MWCNT bundle consists of a combination of SWCNTs and MWCNTs packed together in parallel. The research objective of this project was to answer the question: how do CNTs compare against Cu as global interconnect materials? We performed a comprehensive comparative analysis of the performance and energy impact of using CNT-based global interconnects over Cu for heterogeneous multi-core CMP applications. Our experimental results indicated that while SWCNTs are not as suitable for global interconnect buses due to their large ohmic resistance and very high delays, global MWCNT buses can provide performance speedups of up to 1.98× for CMP applications. Global interconnect buses implemented with SWCNT bundles and mixed SWCNT/MWCNT bundles also lead to performance gains over copper global buses of up to 1.3× and 1.5× respectively. These gains can be further improved if the CNT mean free path (MFP) lengths and metallic densities are increased with advances in fabrication technology that are actively being explored today.
Power and Performance Enhancements for Embedded Processors
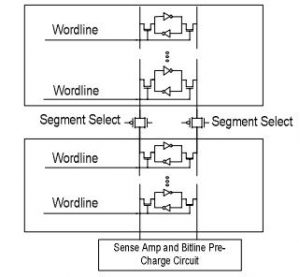
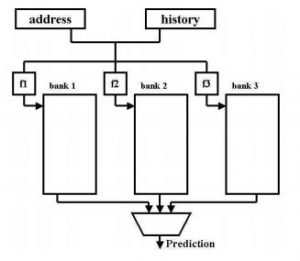
The research objective of this project was to reduce power and improve performance for embedded microprocessors. We designed novel context-switching aware and skew-based branch predictors that improved processor performance by up to 6% over state of the art branch prediction mechanisms. We also devised novel techniques for dynamically resizing the register file (L2MRFS) which in tandem with dynamic frequency scaling (DFS) significantly improves the performance and reduces energy-delay product for embedded processors. Our approach exploited L2 cache misses, adaptively reducing register file (RF) size during the period when there is no pending L2 cache miss, and using a larger RF during the L2 cache miss period. The RF size adaptation is realized using a circuit modification scheme that comes with minimal hardware modification, unlike costly banking or clustering techniques. Our extensive experimental results show that L2MRFS noticeably improves performance (11% on average) and also significantly reduces energy-delay product (7%) for out-of-order embedded processers.